An AI To Learn Your Thoughts

Welcome MindEye2, an AI that may now learn your thoughts! The idea of shared-subject fashions allows fMRI-To-Picture with 1 hour of knowledge. Let’s check out the way it works!
Highlights:
- Medical AI Analysis Middle (MedARC) introduced MindEye2, the predecessor to MindEye1.
- It’s a substantial development in fMRI-to-image reconstruction by introducing the ideas of shared-subject modelling.
- It’s a important enchancment in decoding mind exercise.
MindEye2 Defined
Developments in reconstructing visible notion from mind exercise have been exceptional, but their sensible applicability has but to be restricted.
That is primarily as a result of these fashions are sometimes educated individually for every topic, demanding in depth (Useful Medical Resonance Imaging) fMRI coaching information spanning a number of hours to realize passable outcomes.
Nevertheless, MedARC’s newest research demonstrates high-quality reconstructions with only one hour of fMRI coaching information:
MindEye2 presents a novel useful alignment methodology to beat these challenges. It includes pretraining a shared-subject mannequin, which may then be fine-tuned utilizing restricted information from a brand new topic and generalized to extra information from that topic.
This technique achieves reconstruction high quality similar to that of a single-subject mannequin educated with 40 occasions extra coaching information.
They pre-train their mannequin utilizing seven topics’ information, then fine-tuning on a minimal dataset from a brand new topic.
MedARC’s research paper defined their revolutionary useful alignment method, which includes linearly mapping all mind information to a shared-subject latent area, succeeded by a shared non-linear mapping to the CLIP (Contrastive Language-Picture Pre-training) picture area.
Subsequently, they refine Secure Diffusion XL to accommodate CLIP latent as inputs as a substitute of textual content, facilitating mapping from CLIP area to pixel area.
This technique enhances generalization throughout topics with restricted coaching information, attaining state-of-the-art picture retrieval and reconstruction metrics in comparison with single-subject approaches.
The MindEye2 Pipeline
MindEye2 makes use of a single mannequin educated by way of pretraining and fine-tuning, mapping mind exercise to the embedding area of pre-trained deep-learning fashions. Throughout inference, these brain-predicted embeddings are enter into frozen picture generative fashions for translation to pixel area.
The reconstruction technique includes retraining the mannequin with information from 7 topics (30-40 hours every) adopted by fine-tuning with information from a further held-out topic.
Single-subject fashions had been educated or fine-tuned on a single 8xA100 80Gb GPU node for 150 epochs with a batch measurement of 24. Multi-subject pretraining used a batch measurement of 63 (9 samples per topic). Coaching employed Huggingface Speed up and DeepSpeed Stage 2 with CPU offloading.
The MindEye2 pipeline is proven within the following picture:
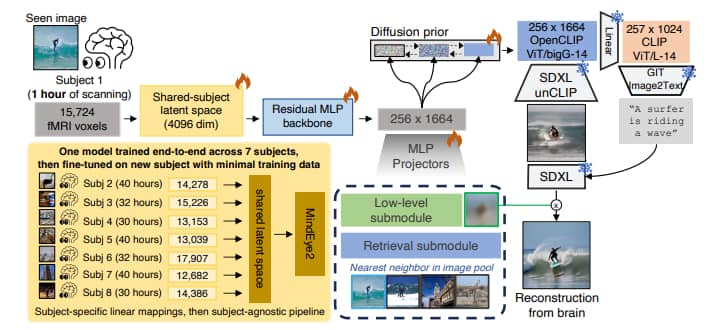
The schematic of MindEye2 begins with coaching the mannequin utilizing information from 7 topics within the Pure Scenes Dataset, adopted by fine-tuning on a held-out topic with restricted information. Ridge regression maps fMRI exercise to a shared-subject latent area.
An MLP spine and diffusion prior generate OpenCLIP ViT-bigG/14 embeddings, utilized by SDXL unCLIP for picture reconstruction. The reconstructed pictures endure refinement with base SDXL.
Submodules retain low-level info and help retrieval duties. Snowflakes symbolize frozen fashions for inference, whereas flames point out actively educated parts.
Shared-Topic Useful Alignment
To accommodate numerous mind constructions, MindEye2 employs an preliminary alignment step utilizing subject-specific ridge regression. Not like anatomical alignment strategies, it maps flattened fMRI exercise patterns to a shared-subject latent area.
MedARC stated the next about it:
“The key innovation was to pretrain a latent space shared across multiple people. This reduced the complexity of the task since we could now train our MindEye2 model from a good starting point.”
Every topic has a separate linear layer for this mapping, making certain sturdy efficiency in numerous settings. The mannequin pipeline stays shared throughout topics, permitting flexibility for brand new information assortment with out predefined picture units.
Spine, Diffusion Prior, & Submodules
In MindEye2, mind exercise patterns are first mapped to a shared-subject area with 4096 dimensions. Then, they move by way of an MLP spine with 4 residual blocks. These representations are additional remodeled right into a 256×1664-dimensional area of OpenCLIP ViT-bigG/14 picture token embeddings.
Concurrently, they’re processed by way of a diffusion prior and two MLP projectors for retrieval and low-level submodules.
Not like MindEye1, MindEye2 makes use of OpenCLIP ViT-bigG/14, provides a low-level MLP submodule, and employs three losses from the diffusion prior, retrieval submodule, and low-level submodule.
Picture Captioning
To foretell picture captions from mind exercise, they first convert the expected ViT-bigG/14 embeddings from the diffusion earlier than CLIP ViT/L-14 area. These embeddings are then fed right into a pre-trained Generative Picture-to-Textual content (GIT) mannequin, a way beforehand proven to work nicely with mind exercise information.
Since there was no present GIT mannequin suitable with OpenCLIP ViT-bigG/14 embeddings, they independently educated a linear mannequin to transform them to CLIP ViT-L/14 embeddings. This step was essential for compatibility.
Caption prediction from mind exercise enhances decoding approaches and assists in refining picture reconstructions to match desired semantic content material.
Tremendous-tuning Secure Diffusion XL for unCLIP
CLIP aligns pictures and textual content in a shared embedding area, whereas unCLIP generates picture variations from this area again to pixel area. Not like prior unCLIP fashions, this mannequin goals to faithfully reproduce each low-level construction and high-level semantics of the reference picture.
To attain this, it fine-tunes the Secure Diffusion XL (SDXL) mannequin with cross-attention layers conditioned solely on picture embeddings from OpenCLIP ViT-bigG/14, omitting textual content conditioning attributable to its damaging impression on constancy.

Mannequin Inference
The reconstruction pipeline begins with the diffusion prior’s predicted OpenCLIP ViT4 bigG/14 picture latents fed into SDXL unCLIP, producing preliminary pixel pictures. These might present distortion (“unrefined”) attributable to mapping imperfections to bigG area.
To enhance realism, unrefined reconstructions move by way of base SDXL for image-to-image translation, guided by MindEye2’s predicted captions. Skipping the preliminary 50% of denoising diffusion timesteps, refinement enhances picture high quality with out affecting picture metrics.
Analysis of MindEye2
MedARC utilized the Pure Scenes Dataset (NSD), an fMRI dataset containing responses from 8 topics who seen 750 pictures for 3 seconds every throughout 30-40 hours of scanning throughout separate classes. Whereas most pictures had been distinctive to every topic, round 1,000 had been seen by all.
They adopted the usual NSD practice/check break up, with shared pictures because the check set. Mannequin efficiency was evaluated throughout numerous metrics averaged over 4 topics who accomplished all classes. Take a look at samples included 1,000 repetitions, whereas coaching samples totalled 30,000, chosen chronologically to make sure generalization to held-out check classes.
fMRI-to-Picture Reconstruction
MindEye2’s efficiency on the total NSD dataset demonstrates state-of-the-art outcomes throughout numerous metrics, surpassing earlier approaches and even its personal predecessor, MindEye1.
Curiously, whereas refined reconstructions usually outperform unrefined ones, subjective preferences amongst human raters recommend a nuanced interpretation of reconstruction high quality.
These findings spotlight the effectiveness of MindEye2’s developments in shared-subject modelling and coaching procedures. Additional evaluations and comparisons reinforce the prevalence of MindEye2 reconstructions, demonstrating its potential for sensible purposes in fMRI-to-image reconstruction.
The picture beneath exhibits reconstructions from totally different mannequin approaches utilizing 1 hour of coaching information from NSD.

- Picture Captioning: MindEye2’s predicted picture captions are in comparison with earlier approaches, together with UniBrain and Ferrante, utilizing numerous metrics equivalent to ROUGE, METEOR, CLIP, and Sentence Transformer. MindEye2 persistently outperforms earlier fashions throughout most metrics, indicating superior captioning efficiency and high-quality picture descriptions derived from mind exercise.
- Picture/Mind Retrieval: Picture retrieval metrics assess the extent of detailed picture info captured in fMRI embeddings. MindEye2 enhances MindEye1’s retrieval efficiency, attaining almost excellent scores on benchmarks from earlier research. Even when educated with simply 1 hour of knowledge, MindEye2 maintains aggressive retrieval efficiency.
- Mind Correlation: To judge reconstruction constancy, we use encoding fashions to foretell mind exercise from reconstructions. This methodology gives insights past conventional picture metrics, assessing alignment independently of the stimulus picture. “Unrefined” reconstructions typically carry out finest, indicating that refinement might compromise mind alignment whereas enhancing perceptual qualities.
How MindEye2 beats its predecessor MindEye1?
MindEye2 improves upon its predecessor, MindEye1, in a number of methods:
- Pretraining on information from a number of topics and fine-tuning on the goal topic, moderately than independently coaching the complete pipeline per topic.
- Mapping from fMRI exercise to a richer CLIP area and reconstructing pictures utilizing a fine-tuned Secure Diffusion XL unCLIP mannequin.
- Integrating high- and low-level pipelines right into a single pipeline utilizing submodules.
- Predicting textual content captions for pictures to information the ultimate picture reconstruction refinement.
These enhancements allow the next major contributions of MindEye2:
- Attaining state-of-the-art efficiency throughout picture retrieval and reconstruction metrics utilizing the total fMRI coaching information from the Pure Scenes Dataset – a large-scale fMRI dataset performed at ultra-high-field (7T) power on the Middle of Magnetic Resonance Analysis (CMRR) on the College of Minnesota.
- Enabling aggressive decoding efficiency with solely 2.5% of a topic’s full dataset (equal to 1 hour of scanning) by way of a novel multi-subject alignment process.
The picture beneath exhibits MindEye2 vs. MindEye1 reconstructions from fMRI mind exercise utilizing various quantities of coaching information. It may be seen that the outcomes for MindEye2 are considerably higher, thus exhibiting a serious enchancment due to the novel method:

Conclusion
In conclusion, MindEye2 revolutionizes fMRI-to-image reconstruction by introducing the ideas of shared-subject modelling and revolutionary coaching procedures. With latest analysis exhibiting communication between two AI fashions, we will say there’s a lot in retailer for us!


