Microsoft’s LLMLingua-2 Compresses Prompts By 80% in Measurement

Microsoft not too long ago launched a analysis paper on LLMLingua 2, a novel compression mannequin for immediate compression. Let’s have a look at the way it works!
Highlights:
- Microsoft Analysis launched LLMLingua 2, a novel strategy for task-agnostic immediate compression.
- It will probably cut back the lengths of prompts to as small as 20 % of the unique immediate whereas functioning 3-6x quicker than its predecessor LLMLingua
- It’s brazenly out there to be used on open-source collaboration platforms GitHub and HuggingFace.
Why do we have to Compress Prompts?
Optimizing the size of a immediate is essential. Longer prompts can result in increased prices and elevated latency which is able to have an effect on the general efficiency of a mannequin. It will damage the LLM when it comes to its effectivity.
There are numerous challenges related to lengthy prompts:
- Increased Prices: Working Massive Language Fashions (LLMs), particularly when coping with prolonged prompts, can incur vital computational bills. Longer prompts want excessive computational sources to course of, thus contributing to increased operational prices.
- Elevated Latency: The processing of prolonged prompts consumes a better period of time which in flip slows down the response time of LLs. Such delays can rescue the effectivity of AI-generated outputs
To beat these points, prompts need to be compressed in order that the efficiency of LLMs might be optimized. Some great benefits of immediate compression are:
- Improved Effectivity: Compression of prompts reduces the time required by LLMs to course of knowledge. This results in quicker response occasions and improved effectivity.
- Optimised Useful resource Utilization: Smaller prompts be certain that AI methods perform effectively with none pointless overhead. This ensures that computational sources are optimally utilized.
- Price Discount: By shortening prompts, computational sources required to function LLM might be decreased, thus leading to value financial savings.
Compressing a immediate is not only about shortening its size and decreasing its phrases. Slightly, it’s about understanding the precise that means of the immediate after which suitably decreasing its size. That’s the place LLMLingua2 is available in.
What’s LLMLingua 2?
LLMLingua 2 is a compression mannequin developed by Microsoft Analysis for task-agnostic compression of prompts. This novel task-agnostic methodology ensures that this system works throughout numerous duties, thus eliminating the requirement for particular changes primarily based on completely different duties each time.
LLMLingua 2 employs clever compression methods to shorten prolonged prompts by eliminating redundant phrases or tokens whereas preserving necessary info. Microsoft Analysis claims that LLMLingua 2 is 3-6 occasions quicker than its predecessor LLMLingua and related methodologies.
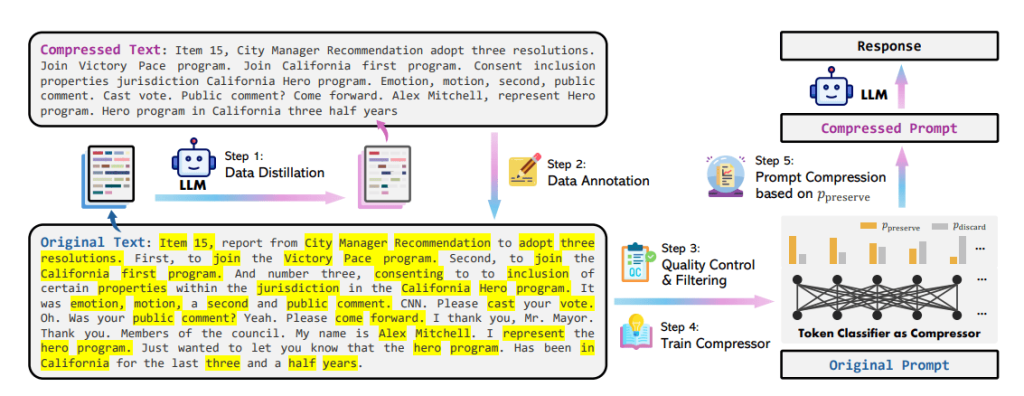
The steps concerned on this method are:
Knowledge Distillation
To extract data from the LLM for efficient immediate compression, LLMLingua 2 prompts GPT-4 to generate compressed texts from unique texts that fulfill the next standards:
- Token discount
- Informativeness
- Faithfulness
Nevertheless, the crew growing LLMLingua 2 discovered that distilling such knowledge from GPT-4 is a difficult course of because it doesn’t constantly observe directions.
Experiments decided that GPT-4 struggles to retain important info from texts. GPT-4 tended to switch expressions within the unique content material and generally got here up with hallucinated content material. So, to beat this, they got here up with an answer for distillation.
To make sure the textual content stays trustworthy, they explicitly instructed GPT4 to compress the textual content by discarding unimportant phrases within the unique texts solely and never including any new phrases throughout era.
To make sure token discount and informativeness, earlier research had specified both a compression ratio or a goal variety of compressed tokens within the directions.
Nevertheless, GPT-4 typically fails to stick to this. The density of textual content might differ relying on the style, and magnificence. Additionally, inside a particular area, the knowledge density from completely different folks might differ.
These components steered {that a} compression ratio may not be optimum. So, they eliminated this restriction from the directions and as a substitute prompted GPT04 to compress the unique textual content as brief as potential whereas retaining as a lot important info as possible.
Given under are the directions used for compression:

Additionally they evaluated a couple of different directions that have been proposed in LLMLingua. Nevertheless, these directions weren’t optimum for LLMLingua 2. The directions are:

Knowledge Annotation
The compressed variations from the earlier step are in comparison with the unique variations to create a coaching dataset for the compression mannequin. On this dataset, each phrase within the unique immediate is labelled indicating whether or not it’s important for compression.
High quality Management
The 2 high quality metrics to evaluate the standard of compressed texts and robotically annotated labels are:
- Variation Price: It measures the proportion of phrases within the compressed textual content which are absent within the unique textual content
- Alignment Hole: That is used to measure the standard of the annotated labels
Compressor
They framed immediate compression as a binary token classification downside, distinguishing between preservation and discarding, guaranteeing constancy to the unique content material whereas sustaining the low latency of the compression mannequin.
A Transformer encoder is utilized because the function extractor for the token classification mannequin, leveraging bidirectional context info for every token.
Immediate Compression
When a immediate is supplied, the compressor skilled within the earlier step identifies the important thing knowledge and generates a shortened model whereas additionally retaining the important info that can make the LLM carry out successfully.
Coaching Knowledge
They used an extractive textual content compression dataset that contained pairs of unique texts from the MeetingBank dataset together with their compressed textual content representations. The compressor has been skilled utilizing this dataset.
Immediate Reconstruction
Additionally they tried immediate reconstruction by conducting experiments of prompting GPT-4 to reconstruct the unique immediate from the compressed immediate generated by LLMLingua 2. The outcomes confirmed that GPT-4 might successfully reconstruct the unique immediate. This confirmed that there was no important info misplaced in the course of the compression part.
LLMLingua 2 Immediate Compression Instance
The instance under reveals compression of about 2x. Such a large discount within the immediate dimension will assist cut back prices and latency and thus enhance the effectivity of the LLM.
The instance has been taken from the research paper.
One other latest improvement from Microsoft to examine is Orca-Math which may resolve large math issues utilizing a small language mannequin.
Conclusion
LLMLingua 2 represents a transformative strategy for immediate compression to assist minimize prices and latency for working an LLM whereas retaining important info. This progressive strategy not solely facilitates quicker and streamlined immediate processing but additionally allows task-agnostic immediate compression, thereby unleashing the complete potential of LLMs throughout various use instances.


