The New AI Coding Asset

Highlights:
- Stability AI simply launched Secure Code Instruct 3B, an instruction-tuned Code Language Mannequin that may deal with duties similar to code technology, software program improvement, and math operations.
- It outperforms comparable fashions similar to Codellama 7B Instruct, and DeepSeek-Coder Instruct 1.3B in numerous coding-related duties.
- The weights and code for Secure Code Instruct 3D can be found publicly on HuggingFace from the place customers can take a look at it mannequin for non-commercial makes use of.
What’s Secure Code Instruct 3B?
Secure Code Instruct 3B is Stability AI’s newest instruction-tuned giant language mannequin (LLM), constructed on high of Secure Code 3B. This mannequin enhances code completion and has assist for pure language interactions, aiming to enhance the effectivity of programming, math, and software program improvement associated duties.
Stability AI introduced the Instruct 3B model with the next publish on X:
Introducing Secure Code Instruct 3B, our new instruction tuned LLM primarily based on Secure Code 3B. With pure language prompting, this mannequin can deal with quite a lot of duties similar to code technology, math and different software program engineering associated outputs.
This mannequin’s efficiency rivals… pic.twitter.com/RsZhKpWu57
— Stability AI (@StabilityAI) March 25, 2024
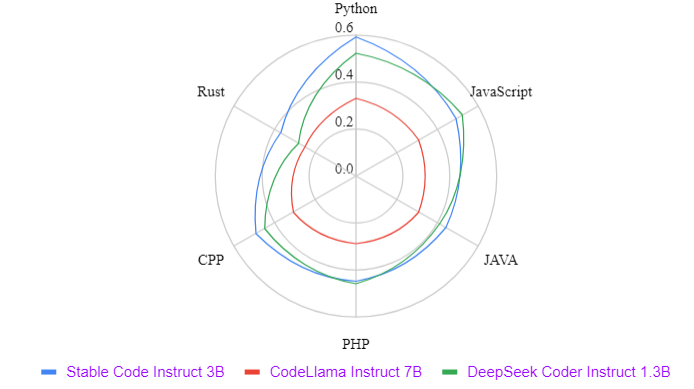
Stability AI’s evaluation means that Instruct 3B outperforms comparable fashions like Codellama 7B Instruct and DeepSeek-Coder Instruct 1.3B in a number of coding-related duties. Secure Code Instruct additionally displays state-of-the-art (SOTA) efficiency on the MT-Bench coding duties and Multi-PL completion in comparison with different instruction-tuned fashions.
Their evaluation means that Secure Code Instruct 3B outperforms comparable fashions similar to Codellama 7B Instruct, and DeepSeek-Coder Instruct 1.3B in numerous coding-related duties.
The mannequin is on the market with a Stability AI Membership for business use. The weights and code for Secure Code Instruct 3B are actually out there on Hugging Face. Customers can take a look at the mannequin totally free utilizing HuggingFace and might obtain the weights and code for non-commercial use.
What can Secure Code Instruct 3B do? Right here’s the listing:
- Automated Code Completion
- Insertion of Lacking Code Snippets
- Code Technology for Database Interplay
- Translation of Programming Languages
- Clarification of Code Performance
- Code Technology Based mostly on Consumer Directions
Coaching Information for Secure Code Instruct 3B
To make the pre-training dataset for Secure Code, the group gathered numerous knowledge from numerous publicly out there sources, together with code repositories, technical paperwork, mathematical texts, and intensive net datasets.
The first purpose of this preliminary pretraining part was to develop a complete inner illustration that goes past mere code understanding. Their aim was to considerably improve the mannequin’s proficiency in mathematical comprehension, logical reasoning, and processing complicated technical texts associated to software program improvement.
By deciding on such a various dataset combine, they aimed to create a language mannequin well-equipped to deal with a variety of software program engineering duties, not restricted to code completion alone. Moreover, the coaching knowledge incorporates common textual content datasets to supply the mannequin with broader linguistic information and context.
1) Artificial Dataset
They included a small artificial dataset into the pre-training corpus, generated from the seed prompts of the CodeAlpaca dataset, consisting of 174,000 prompts. To reinforce the variety and complexity of the prompts, they utilized the “Evol-Instruct” technique
This technique entails progressively growing the complexity of seed prompts utilizing a language mannequin, on this case, WizardLM, by way of methods that concentrate on breadth, reasoning, deepening, and complexity.
Consequently, they augmented the dataset with an extra 100,000 prompts. They employed the DeepSeek Coder 34B mannequin to generate artificial outputs for the newly developed “Evol-Instruct” prompts. This early introduction of artificial knowledge through the pretraining part aimed to enhance the mannequin’s skill to answer pure language textual content.
2) Lengthy-Context Dataset
Increasing upon the preliminary pre-training part, in addition they developed an extra coaching stage targeted on enhancing the mannequin’s skill to course of and perceive lengthy sequences, significantly helpful for coding fashions coping with a number of information inside a repository.
After analyzing the median and imply token counts in software program repositories, they decided a context size of 16,384 tokens.
On this stage, they utilized a curated choice of programming languages from The Starcoder dataset, together with programming languages similar to Python, Java, Javascript, C, C++, and GoLang primarily based on the insights supplied by the 2023 Stack Overflow Developer Survey.
These are the languages which might be most utilized by builders. Aside from these languages, in addition they included coaching for various broadly adopted languages like SQL, PHP, and Rust.
The lengthy context dataset was created by combining information from these languages inside a repository, with a particular <repo_continuation> token inserted between every file for separation whereas sustaining content material circulate. They employed a randomized technique to generate two distinct orderings for every repository to keep away from potential biases from mounted file orderings.
Multi-Stage Coaching
They adopted a staged coaching methodology, a technique generally employed in different comparable sturdy code language fashions like CodeGen, Secure Code Alpha, CodeLLaMA, and DeepSeekCoder fashions. In coaching Secure Code, they make the most of normal autoregressive sequence modelling to foretell the following token.
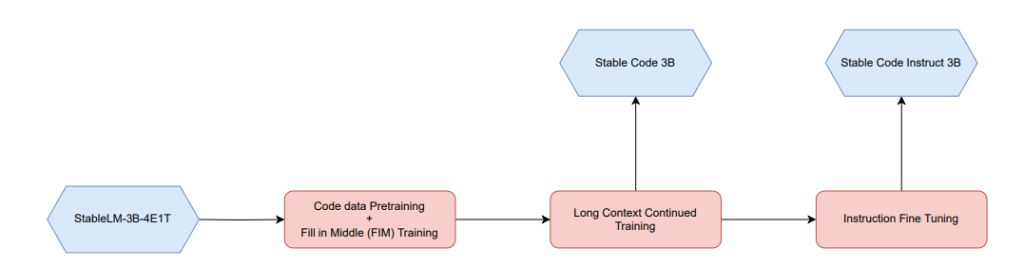
The mannequin has been initialized from the Secure LM 3B checkpoint, with a base context size of 4096 for the preliminary coaching stage, incorporating the desired knowledge combine. Subsequently, a continued pretraining stage follows, as illustrated within the determine beneath.
Fill within the Center (FIM) Coaching
Using the “Fill in the Middle” (FIM) goal is a technique adopted to deal with the problem posed by the non-linear ordering of tokens in code, which regularly deviates from the left-to-right causal ordering noticed in pure language.
This method entails randomly dividing a doc into three segments – prefix, center, and suffix – after which relocating the center section to the top of the doc earlier than persevering with with the autoregressive coaching course of.
By doing so, the mannequin can be taught to situation structural patterns past the normal prefix-only format typical in causal language modelling.
The info augmented by way of this course of is categorized into two modes: “Suffix-Prefix-Middle” (SPM) and “Prefix-Suffix-Middle” (PSM), with FIM utilized on the character stage with a charge of fifty%, and the selection between SPM and PSM modes decided uniformly.
This FIM method is applied throughout each levels of pretraining. To make sure consistency with FIM within the lengthy context coaching part, precautions are taken to limit its software inside particular person information, thus stopping the introduction of unrealistic eventualities into the coaching goal.
High quality-tuning and Alignment
After finishing pre-training, the mannequin’s skills are additional enhanced by way of a fine-tuning stage, which entails each Supervised High quality-Tuning (SFT) and Direct Desire Optimization (DPO).
For SFT, publicly out there datasets similar to OpenHermes, Code Suggestions, and CodeAlpaca are utilized, offering roughly 500,000 coaching samples post-dedication.
Following SFT, DPO is utilized, leveraging a dataset of roughly 7,000 samples curated from UltraFeedback and Distilabel Capybara DPO-7k Binarized. To make sure mannequin security, samples associated to code are filtered utilizing an LLM-based method, and extra datasets like Useful and Innocent RLFH are included.
Outcomes
The primary benchmark used for comparability is the mannequin’s proficiency in code completion duties, which is essential for assessing its sensible applicability in code-related contexts. They use the Multi-PL benchmark because the standardized analysis metric for these assessments.
The picture beneath reveals the efficiency of Code Instruct 3B versus different comparable instruction-tuned LLMs with 3B parameters.
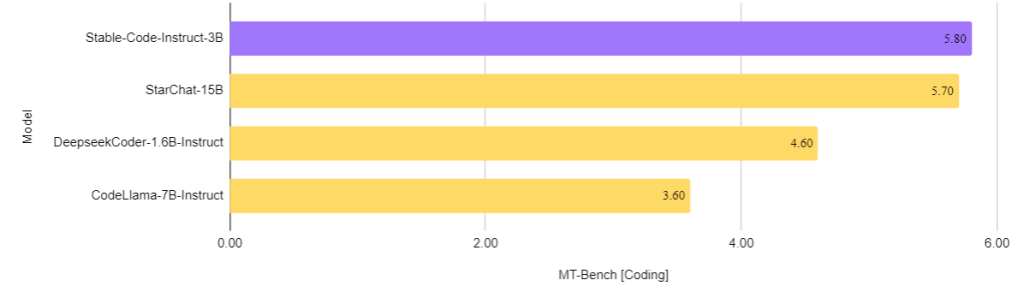
In addition they evaluated instruction-tuned fashions on the code subset of the difficult Multi-turn benchmark (MT-Bench). The picture beneath reveals the outcomes of coding questions in MT-Bench.
One other necessary software for code language fashions is database question duties. For this, they in contrast the efficiency of Secure Code Instruct 3B towards different in style instruction-tuned fashions and fashions particularly skilled to carry out effectively in SQL.
They use the benchmark created by Defog AI to guage the fashions. The outcomes are proven within the desk beneath.

Examples
Let’s take a look at Code Instruct 3B by way of HuggingFace. You will note an interface that appears like this:

Prompted the mannequin to finish the code for the bubble kind algorithm. Right here, the mannequin efficiently performs FIM (Fill within the center):
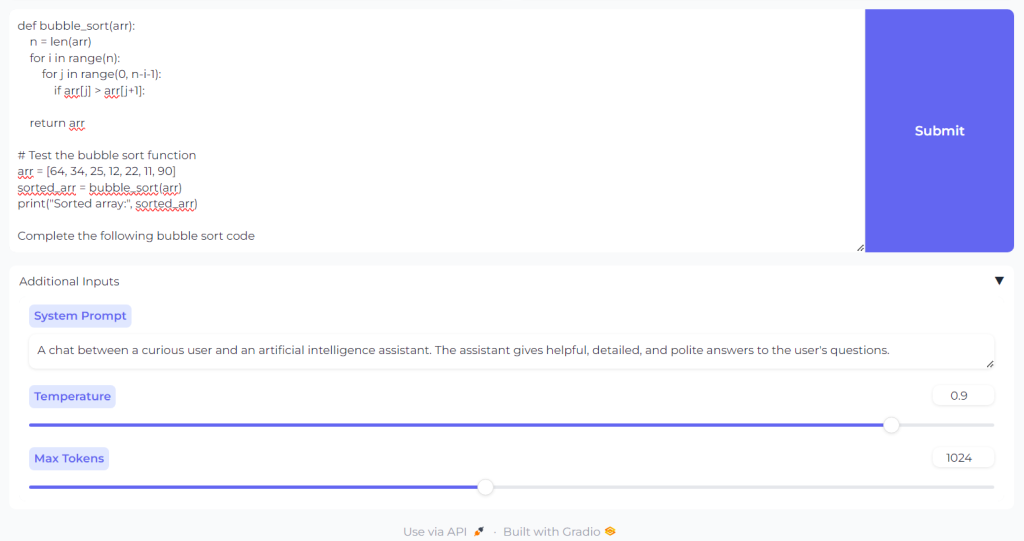
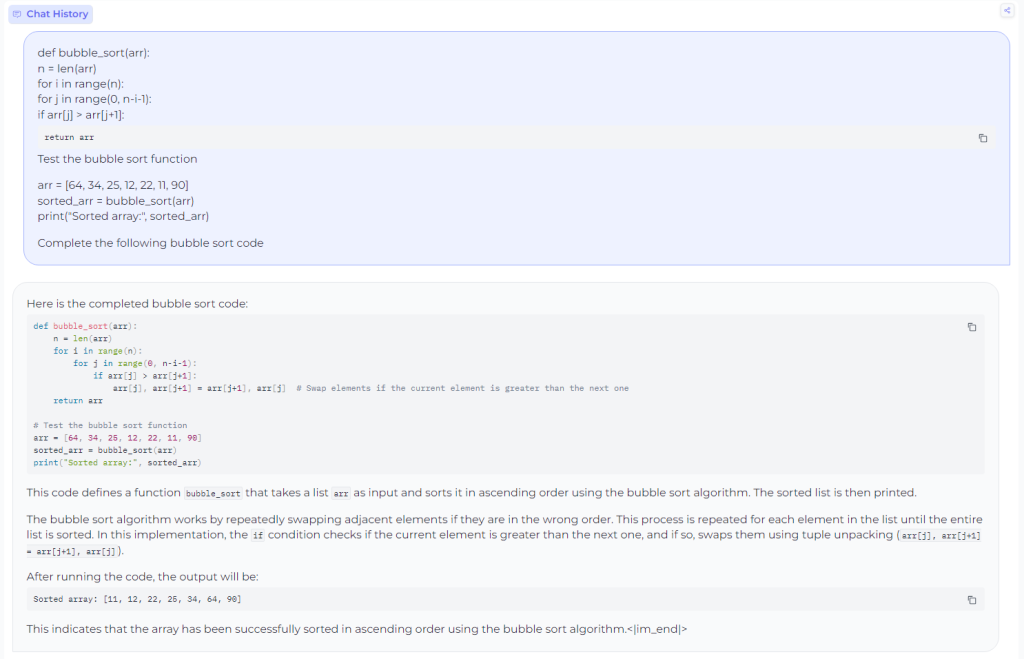
Prompted the mannequin to clarify a code snippet:
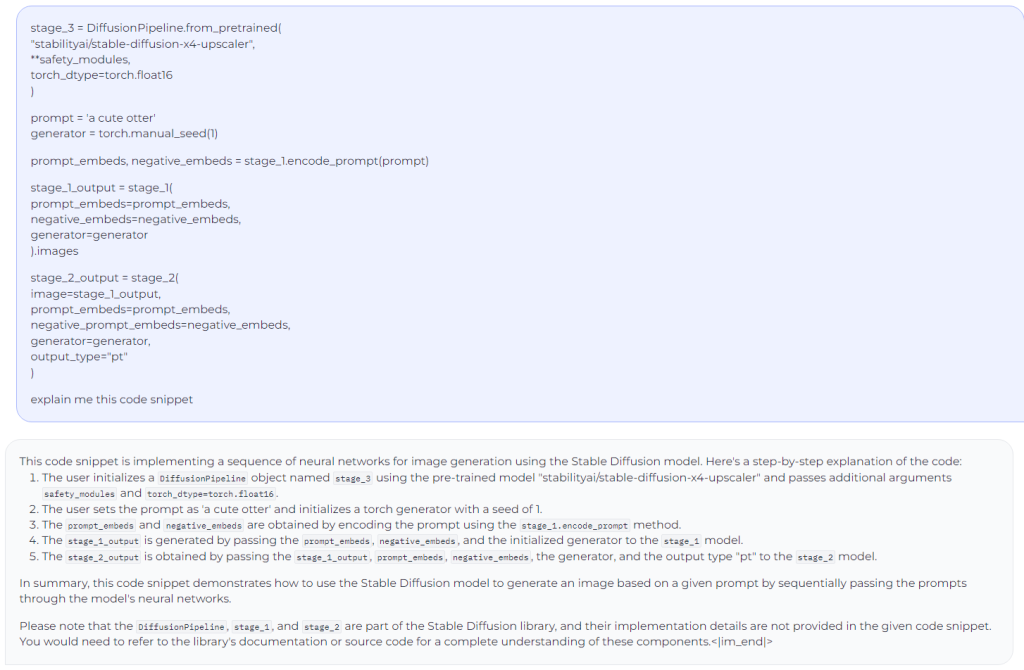
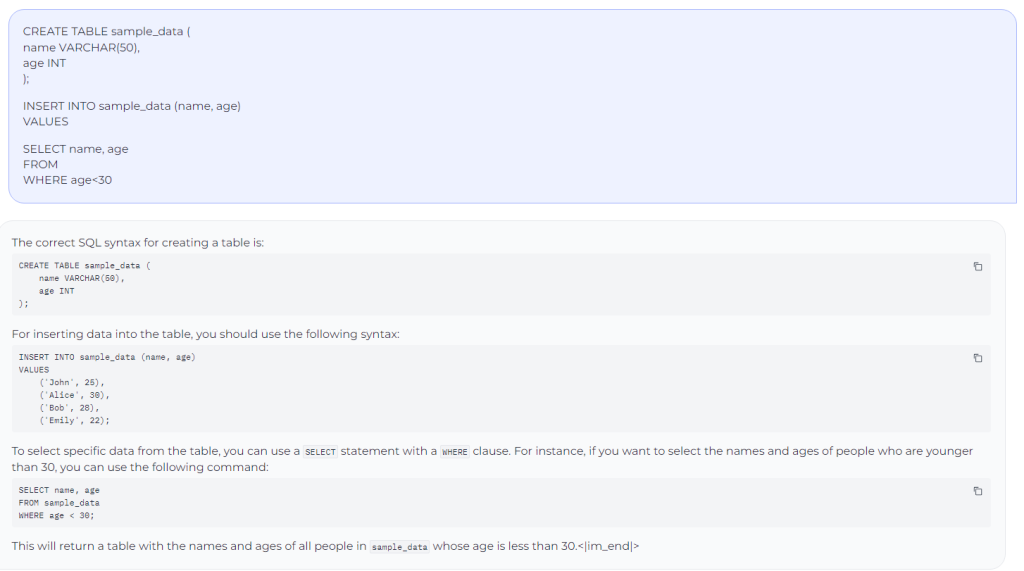
Prompted the mannequin to finish an incomplete SQL code:
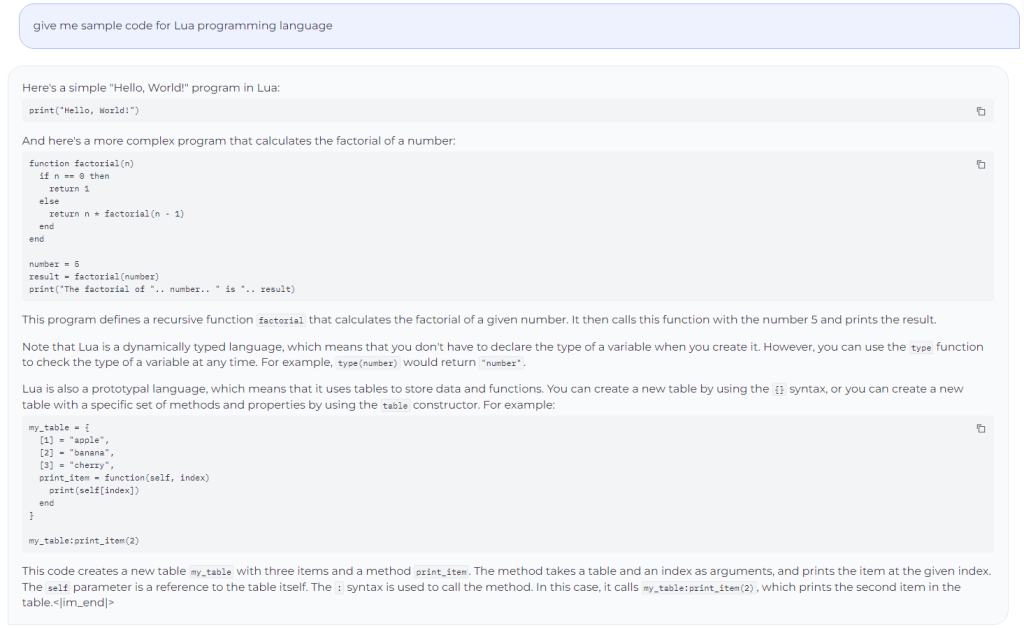
Secure Code Instruct 3B delivers sturdy take a look at efficiency even in languages that weren’t initially included within the coaching set, similar to Lua. The instance beneath reveals how the mannequin can present a easy code within the Lua language.
This proficiency could stem from its understanding of the underlying coding rules and its skill to adapt these ideas throughout numerous programming environments.
Conclusion
Secure Code Instruct 3B represents a big development in instruction-tuned Code Language Fashions, excelling in code technology, FIM (Fill within the center) duties, database queries, translation, clarification, and creation.
Its instruction comprehension permits numerous coding duties past completion, with superior efficiency throughout normal benchmarks promising transformative impacts within the area of software program engineering.


