This New AI System constructed with GPT-4 Can Predict Future Occasions
Identical to people, now AI might be skilled to foretell what is going to occur! Not less than, that’s what this new system can do.
Highlights:
- Researchers on the College of Berkeley developed an AI forecasting system that may equal human-level knowledge.
- They constructed a retrieval-augmented LM system utilizing GPT-4 to generate forecasts and predict future occasions.
- The outcomes present that the predictions would possibly surpass human scores throughout various features.
AI Forecasting System constructed with GPT-4
The world of generative AI retains on evolving as Language Fashions hold arising with new capabilities every day. This new study exhibits us one other facet of LMs as they are often helpful for constructing AI forecasting methods.
A gaggle of researchers from the College of Berkeley, California, made an AI forecasting system that may compete with human-level forecasting capabilities, with out the shortcomings reminiscent of bills, time delays, and application-specific area issues.
Since LLMs aren’t designed with occasion forecasting in thoughts, the scientists used retrieval-augmented reasoning to construct a forecasting system on high of GPT-4. By a collection of steps, GPT-4 was skilled to search out related data, consider its applicability, and incorporate it into its reasoning course of earlier than producing a forecast.
“Forecasting future events is important for policy and decision making. In this work, we study whether language models (LMs) can forecast at the level of competitive human forecasters. Towards this goal, we develop a retrieval-augmented LM system designed to automatically search for relevant information, generate forecasts, and aggregate predictions.”
Lately, an analogous vital analysis exhibits that AI fashions can talk with one another, so, quite a bit is going on in these occasions.
How is AI Forecasting an Enchancment?
Until now at any time when people have carried out forecasting, they’ve executed it in two strategies, specifically statistical and judgmental.
Time-series modelling strategies are the principle instruments utilized in statistical forecasting. This technique works greatest when there’s a considerable amount of knowledge with little distributional motion.
In distinction, human forecasters use historic knowledge, topic experience, Fermi estimates, and instinct to assign possibilities to future occasions primarily based on their judgments. They collect knowledge from numerous sources and make selections relying on the precise work conditions.
This makes it attainable to make dependable projections even within the case of few historic observations or massive distributional shifts.
Nonetheless, Forecasting might be pricey, sluggish, or solely helpful in sure fields because it will depend on human labour and expertise. Moreover, nearly all of human projections have little to no explanatory content material. That is the place the necessity for language fashions in AI forecasting methods is available in.
LMs can rapidly and affordably make forecasts as a consequence of their speedy textual content parsing and manufacturing capabilities. They’ve intensive, cross-domain information since they’ve been pre-trained on web-scale knowledge.
Moreover, we are able to research them to partially comprehend the ultimate forecast as a result of we are able to elicit their reasonings by way of prompts.
Trying Into the Forecasting Mannequin
The scientists targeted on anticipating binary outcomes once they constructed an LM pipeline for automated forecasting.

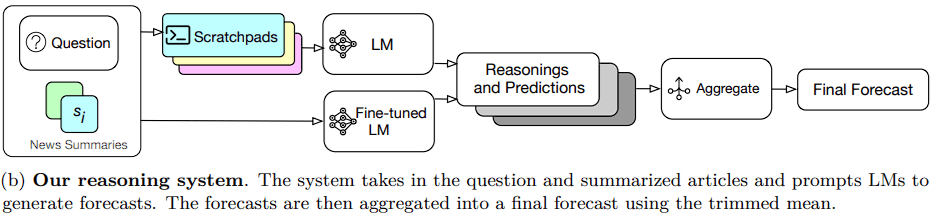
Three important parts of the standard forecasting technique are applied and automatic by their system.
The three steps are as follows: retrieval, which compiles pertinent data from information sources; reasoning, which assesses the info at hand and creates a forecast; and aggregation, which mixes a number of predictions right into a single prediction.
Each stage makes use of a set of prompted or fine-tuned studying modules (LMs). Let’s look into every step, intimately:
1) Retrieval
4 phases make up the retrieval system: creating search queries, retrieving information, reranking and filtering content material primarily based on relevancy, and summarising materials. To entry historic articles, the information APIs are first known as upon by the system’s generated search queries.
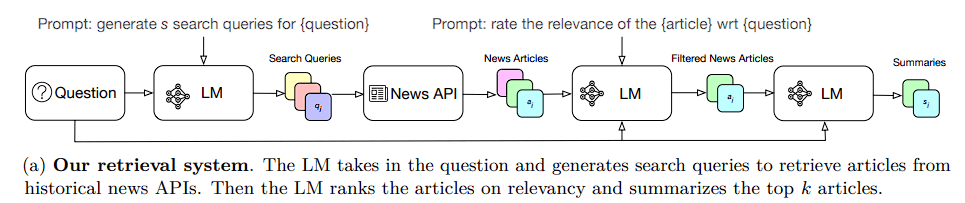
Utilizing a easy question growth immediate at first, the researchers advised the mannequin to generate questions relying on the query and its context. The researchers instructed the mannequin to interrupt down the forecasting query into smaller queries and use every to create a search question to acquire wider protection.
Subsequent, utilizing the search queries supplied by LM, the system pulls articles from information APIs. The researchers selected NewsCatcher and Google Information after evaluating 5 APIs for the relevancy of the articles they retrieved.
On the expense of getting sure irrelevant articles, the preliminary retrieval presents intensive protection. They instructed GPT-3.5-Turbo to fee the relevancy of each article and get rid of these with poor scores to verify they don’t deceive the mannequin through the reasoning step.
The researchers summed up the papers since LMs are constrained by their context window. They instructed GT-3.5-Turbo to extract probably the most pertinent data on the forecasting matter from each article. Ultimately, they ranked the highest okay article summaries in accordance with relevance and gave them to the LM.
2) Reasoning
The reasoning paths of the mannequin had been organized by the researchers utilizing an open-ended scratchpad. Their immediate begins with asking about the problem, giving a proof, outlining the decision necessities and vital deadlines, after which itemizing the highest okay pertinent summaries.
4 extra parts had been added to the perfect scratchpad immediate to assist the mannequin purpose in regards to the forecasting query.
To make sure the mannequin understood the query, the researchers first had it restate the inquiry. To offer extra particulars, additionally it is advised to broaden the inquiry utilizing what it is aware of. It is smart {that a} query with extra particular and elaborate wording would elicit higher solutions.
They then instructed the mannequin to make use of the information it had recovered and its prior coaching to generate justifications for why the specified end result might or may not come to go. To mitigate the danger of bias and miscalibration, the mannequin was instructed to evaluate its degree of confidence and take previous base charges under consideration. If vital, this allowed the mannequin to calibrate and modify the prediction.
GPT-4 evaluates the condensed articles and generates a complete forecast with a justification through the use of “scratchpad prompts.” These questions direct the mannequin’s reasoning and promote a methodical strategy to reasoning.
3) Aggregation
After fine-tuning GPT-4, the researchers skilled it to provide reasonings with exact predictions. They gave it simply the important particulars of the inquiry as prompts, excluding any scratchpad directions, as a result of their refined mannequin was designed to purpose with out express steerage.
With the addition of self-supervised fine-tuning, the Berkeley crew superior the system even additional. The “wisdom of the crowd,” which is outlined because the collective forecasts of human forecasters, was exceeded by the AI in most of the instances the place they created a major variety of projections on historic queries with recognized solutions.
They elicited a number of predictions from each the bottom and the fine-tuned fashions. As a result of its superior efficiency on the validation set when in comparison with the opposite ensemble strategies that the researchers tried, the system mixed these forecasts right into a remaining prediction by taking their trimmed imply.
General, the researchers skilled GPT-4 to mimic the reasoning patterns that produced probably the most correct projections by fine-tuning them utilizing these cases.
What did the Outcomes present?
The forecasting mannequin confirmed glorious ends in proving to be a worthy human wisdom-level AI forecasting system. When the AI had entry to sufficient pertinent publications on a given matter and was requested questions with excessive human uncertainty early within the forecasting course of, it did particularly effectively.

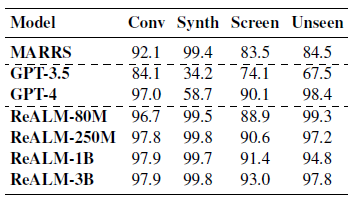
The AI obtained a Brier rating of 0.179 when evaluated on forecasting questions beginning in June 2023, whereas the human forecaster had a rating of 0.149.
When the system had between 0 and 10 related articles, it outperformed a bunch of individuals. The algorithm carried out higher when customers had unsure predictions with confidence ranges between 0.3 and 0.7. The mannequin’s Brier rating was 0.199, whereas customers’ scores had been 0.246.
Nonetheless, people outperformed the mannequin once they had been fairly sure with predictions beneath 0.05.
When knowledge was first being gathered, the accuracy of the system was greater.
Conclusion
Though utilizing AI to forecast vital societal and private occasions continues to be a posh concept to deal with with, it is a main development on the planet of generative AI, and we are able to’t assist however respect the progress!