Apple Dethrones GPT-4 with ReALM, Good for On-Machine AI?

Apple enters the realm of LLMs with ReALM, which may outperform GPT-4! The company is predicted to be launching giant inside the AI race later this yr and this can be their giant reveal for the massive day!
Highlights:
- Apple AI researchers printed a paper on a small AI model known as ReALM.
- This new system can interpret context from on-screen content material materials.
- The paper claims that ReALM’s effectivity is similar to GPT-4 for reference choice.
What’s ReALM?
ReALM, which stands for Reference Choice As Language Modeling, can understand images and textual content material on the show to spice up the interactions with the AI.
The concept of reference choice entails a computer program performing a exercise based on obscure language inputs, corresponding to a shopper saying “this” or “that.” It’s a complicated scenario since pc techniques can’t interpret images one of the best ways folks can. However, Apple seems to have found a streamlined choice using LLMs.
The research paper proposes a novel technique to encode on-screen entities and their spatial relationships proper right into a textual illustration which might be processed by an LLM. That’s completed by parsing the show, sorting the climate based on their place and creating a illustration that preserves the spatial positions of the climate.
There are 4 sizes talked about inside the paper: 80M, 250M, 1B, and 3B. The “M” and “B” characterize the number of parameters in tons of of hundreds and billions, respectively.
The concept supplied this is a recreation changer for Siri interaction.
Whereas interacting with smart assistants, you sometimes current context-dependent information similar to the restaurant you visited ultimate week or the recipe you ultimate appeared for. These are explicit entities based on the earlier and current state of the system.
However, this requires in depth computational sources because of large amount of references that must be processed on a day-to-day basis.
How does ReALM work?
That’s the place the novel technique of ReALM has a big effect. ReALM converts all associated contextual information to textual content material which simplifies the responsibility for the language model.
Given associated entities and a exercise the buyer wants to hold out, the technique must extract the entities which is perhaps pertinent to the current shopper query. The associated entities are of three different types:
- On-screen Entities: These are entities which is perhaps presently displayed on a shopper’s show.
- Conversational Entities: These are entities associated to the dialog. These entities might come from a earlier flip for the buyer (for example, when the buyer says “Call Mom”, the contact for Mom might be the associated entity in question), or from the digital assistant (for example, when the agent provides a shopper with an inventory of areas or alarms to pick from).
- Background Entities: These are associated entities that come from background processes which can not basically be a direct part of what the buyer sees on their show or their interaction with the digital agent; for example, an alarm that begins ringing or music that is having fun with inside the background.
The necessary factor steps involved in altering these entities to textual sorts are:
- Parsing the show: First, ReALM assumes the presence of upstream information detectors which parse the show and extract entities like phone numbers, contact names, and addresses with their bounding bins.
- Sorting parts based on spatial positions: These extracted entities are sorted based on their positions on the show, vertically from excessive to bottom based on the y-coordinates of their bounding discipline. Then a gradual kind is carried out horizontally from left to correct based on the x-coordinates.
- Determining vertical ranges: A margin is printed to group parts which is perhaps inside a positive distance from each other vertically. Components inside this margin are thought-about to be on the an identical horizontal diploma or line.
- Establishing the textual illustration: The sorted parts are then represented in a textual content material format, with parts on the an identical horizontal diploma separated by a tab character, and parts on fully completely different ranges separated by newline characters. This preserves the relative spatial positioning of the climate on the show.
- Injecting flip objects: The entities that must be resolved (referred to as “turn objects”) are injected into this textual illustration by enclosing them in double curly braces {{ }}.
By altering the on-screen information into this textual format, ReALM can leverage the ability of LLMs to know the spatial relationships between entities and resolve references accordingly.
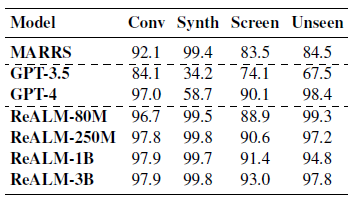
The authors fine-tuned a FLAN-T5 model on diversified datasets consisting of conversational, synthetic, and on-screen references, and demonstrated that their technique (ReALM) outperforms current packages and performs comparably to or larger than GPT-4, no matter using significantly fewer parameters.
This revolutionary encoding method permits ReALM to take care of references to on-screen parts with out relying on difficult seen understanding fashions or multi-modal architectures.
Instead, it leverages the sturdy language understanding capabilities of LLMs whereas providing the required spatial context through textual illustration.
Proper right here is an occasion of how the buyer show is seen by on-screen extractors:

Proper right here is an occasion of how inputs into the model have been encoded, inside the kind of a visual illustration:


This is what the Apple Researchers take into accounts its effectivity:
“We show that ReaLM outperforms previous approaches, and performs roughly as well as the stateof-the-art LLM today, GPT-4, despite consisting of far fewer parameters, even for onscreen references despite being purely in the textual domain.”
By encoding spatial information into textual representations, ReALM outperforms current packages and rivals state-of-the-art fashions using fewer parameters. This fine-tuning technique paves one of the best ways for additional pure and atmosphere pleasant conversations.
Conclusion
This new paper by the Apple researcher and the implementation of this technique will mainly change one of the best ways smart assistants course of contextual information. Apple is shifting forward fast with MM1 fashions as correctly. Let’s await various additional months to know if it entails our palms or not!


