Intel not too way back launched that it is rising its AI PC acceleration program by introducing two new modern initiatives to boost the occasion and deployment of current AI utilized sciences. With the help of these initiatives, Intel objectives to optimize and maximize AI choices all through over 100 million Intel Core Extraordinarily-powered PCs by 2025.
Highlights:
- Intel launched an progress of its AI PC acceleration program by introducing two new initiatives to boost the occasion and deployment of current AI utilized sciences.
- The company plans to introduce better than 300 AI-accelerated choices by the tip of 2024 which can most likely be built-in into over 100 million Intel Core Extraordinarily-powered PCs.
- Intel has partnered with foremost unbiased software program program distributors (ISVs) like Adobe, Webex, and Zoom to mix AI acceleration into their capabilities.
Intel AI PC Acceleration Program
Intel launched the AI PC Acceleration Program to hurry up AI enchancment all through the PC enterprise.
This technique objectives to develop a collaboration between unbiased {{hardware}} distributors (IHVs) and unbiased software program program distributors (ISVs) with an expansion of Intel sources that embody AI toolchains, co-engineering, {{hardware}}, design sources, technical expertise, and co-marketing alternate options.
Michelle Johnston Holthaus, authorities VP and regular supervisor of the Shopper Computing Group at Intel talked about the subsequent regarding the AI PC accelerated program:
“Intel recognizes that software leadership is key to the AI PC experience, and we’re uniquely positioned to lead the industry with an open ecosystem approach. With a long history in AI development and a deep network of ISV engineering relationships, Intel will take an active role in fostering connections and innovations that propel new use cases and experiences on the PC.”
Carla Rodriguez, Vice President and Frequent Supervisor of the Shopper Software program program Ecosystem emphasised the importance of this progress, noting this technique’s transition from primarily involving huge ISVs to now encompassing small and medium-sized players along with aspiring builders.
Via this program, the company objectives to strengthen the developer experience by offering software program program, developer devices, and {{hardware}} built-in with Intel Core Extraordinarily processors. Collaborating with over 150 {{hardware}} distributors worldwide, They intend to introduce better than 300 AI-accelerated choices in 2024 all through over 230 designs from 12 world distinctive gear producers (OEMs).
To advance these initiatives, Intel intends to organize a sequence of native developer events worldwide in strategic areas, very similar to the newest summit held in India. The company plans to have as a lot as ten additional events this yr as part of its ongoing efforts to extend the developer ecosystem.
What does an AI PC do?
The emergence of AI offers vital prospects for integrating novel {{hardware}} and software program program functionalities into the established PC platform. However, the precise definition of an AI PC stays significantly ambiguous.
Numerous firms, equal to Intel, AMD, Apple, and shortly Qualcomm with its X Elite chips, have engineered processors that features devoted AI accelerators built-in alongside typical CPU and GPU cores. However, each agency has its interpretation of what qualifies as an AI PC.
For months now, Intel, Microsoft, Qualcomm, and AMD have been advocating the concept of an “AI PC” as we switch within the path of additional AI-driven choices in House home windows. Whereas finer particulars from Microsoft regarding its AI plans for House home windows are awaited, Intel has begun sharing Microsoft’s requirements for OEMs to manufacture an AI PC.
One among many key requirements is that an AI PC ought to embody Microsoft’s Copilot key.
In response to the latest co-developed definition from Microsoft and Intel, an AI PC will perform a Neural Processing Unit (NPU), along with applicable CPU and GPU elements supporting Microsoft’s Copilot. Furthermore, it might embody a bodily Copilot key situated on the keyboard, altering the second House home windows key generally found on the acceptable aspect.
This implies that certain laptops like Asus’ latest model ROG Zephyrus, that are outfitted with new Core Extraordinarily chips, fail to fulfill Microsoft’s AI PC requirements as they lack a Microsoft Copilot key. However, Intel nonetheless considers them AI PCs.
Whereas they’re collectively promoting this definition for the AI PC thought, Intel offers a simpler definition requiring a CPU, GPU, and NPU, each with devoted AI acceleration capabilities.
Intel envisions distributing AI duties amongst this stuff, leveraging the NPU’s power effectivity for lighter duties like media processing, enhancing battery life, and guaranteeing information privateness. This method frees the CPU and GPU for various duties whereas letting them take care of heavier AI workloads, stopping overload of the NPU.
Furthermore, the NPU and GPU can collaborate on certain duties, along with working an LLM collectively if obligatory.
Choices of AN AI PC
Intel says that AI will enable quite a lot of current choices, nonetheless many of the new use circumstances are undefined because of we’re nonetheless inside the early days of AI adoption.
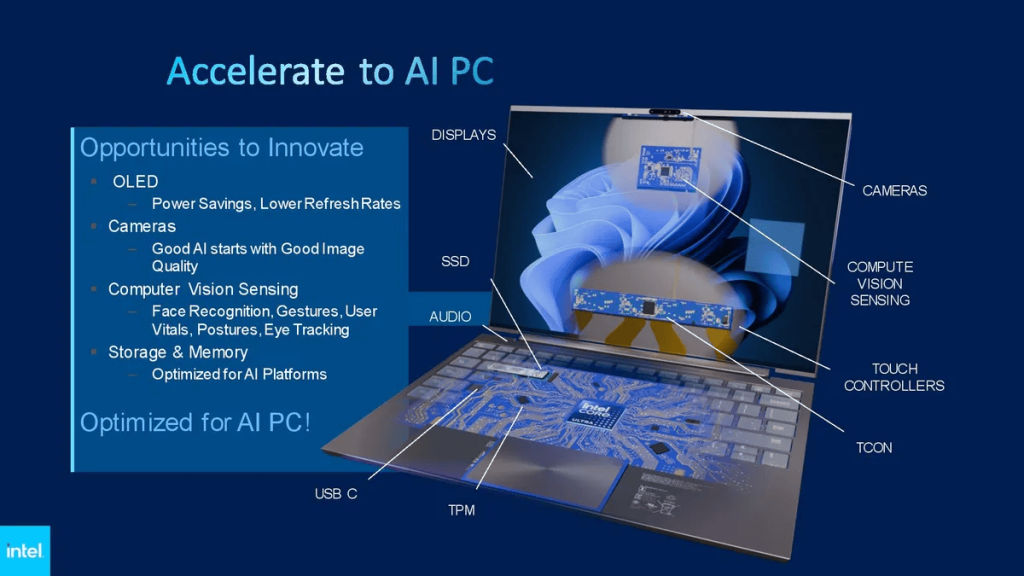
For example, integrating gaze detection with power-saving choices in OLED panels can regulate refresh prices or flip off the show display screen when the individual is away, thus conserving battery life. Capabilities like background segmentation for video conferencing shall be offloaded from the CPU to the NPU, saving power.
This NPU successfully manages sustained AI workloads with minimal power consumption, thereby enhancing power effectivity and rising battery life on laptops. Whereas this may doubtless seem minor, Intel claims it’d lengthen battery life by as a lot as an hour in certain eventualities.
Completely different capabilities embody eye gaze correction, auto-framing, background blurring, noise low cost, audio transcription, and meeting notes, a couple of of which could run instantly on the NPU with help from platforms like Zoom, Webex, and Google Meet.
Companies are moreover creating coding assistants expert on individual information and Retrieval-Augmented Expertise (RAG) fashions for additional appropriate search outcomes.
Additional use circumstances comprise image, audio, and video enhancing choices built-in into software program program suites like Adobe Inventive Cloud. Security is one different focus, with AI-powered anti-phishing software program program in enchancment.
Intel engineers have even created a sign-language-to-text utility using video detection, showcasing the varied range of potential capabilities benefiting clients.
AI PC Program Companions
Intel has already partnered with foremost ISVs like Adobe, Audacity, BlackMagic, BufferZone, CyberLink, DeepRender, Fortemedia, MAGIX, Rewind AI, Skylum, Topaz, VideoCom, Webex, Wondershare Filmora, XSplit and Zoom. The purpose is to optimize their suppliers to take full advantage of the latest expertise of Core Extraordinarily Processor-powered PCs.
How can Builders Be a part of the Program?
Builders critical about turning into a member of the AI PC Acceleration Program can register freed from cost by way of the Intel AI PC enchancment portal. Upon approval, contributors will receive entry to a group of AI and machine finding out devices and sources, along with the Intel OpenVINO toolkit with out cost.
Furthermore, they supply applications and certifications to stay updated on the latest utilized sciences and enhancements. The company will even present technical help and assist to help {{hardware}} distributors optimize and verify their latest utilized sciences.
Conclusion
Intel’s progress of the AI PC acceleration program objectives to strengthen AI enchancment and deployment all through hundreds and hundreds of Core Extraordinarily-powered PCs by 2025. Moreover, be taught regarding the new Light 01 AI Assistant that is one different fascinating technique to mix AI in your life.